What is Tally?
Tally is a service that keeps a running total of aggregate information as we insert data. No more long running queries. Like Caching
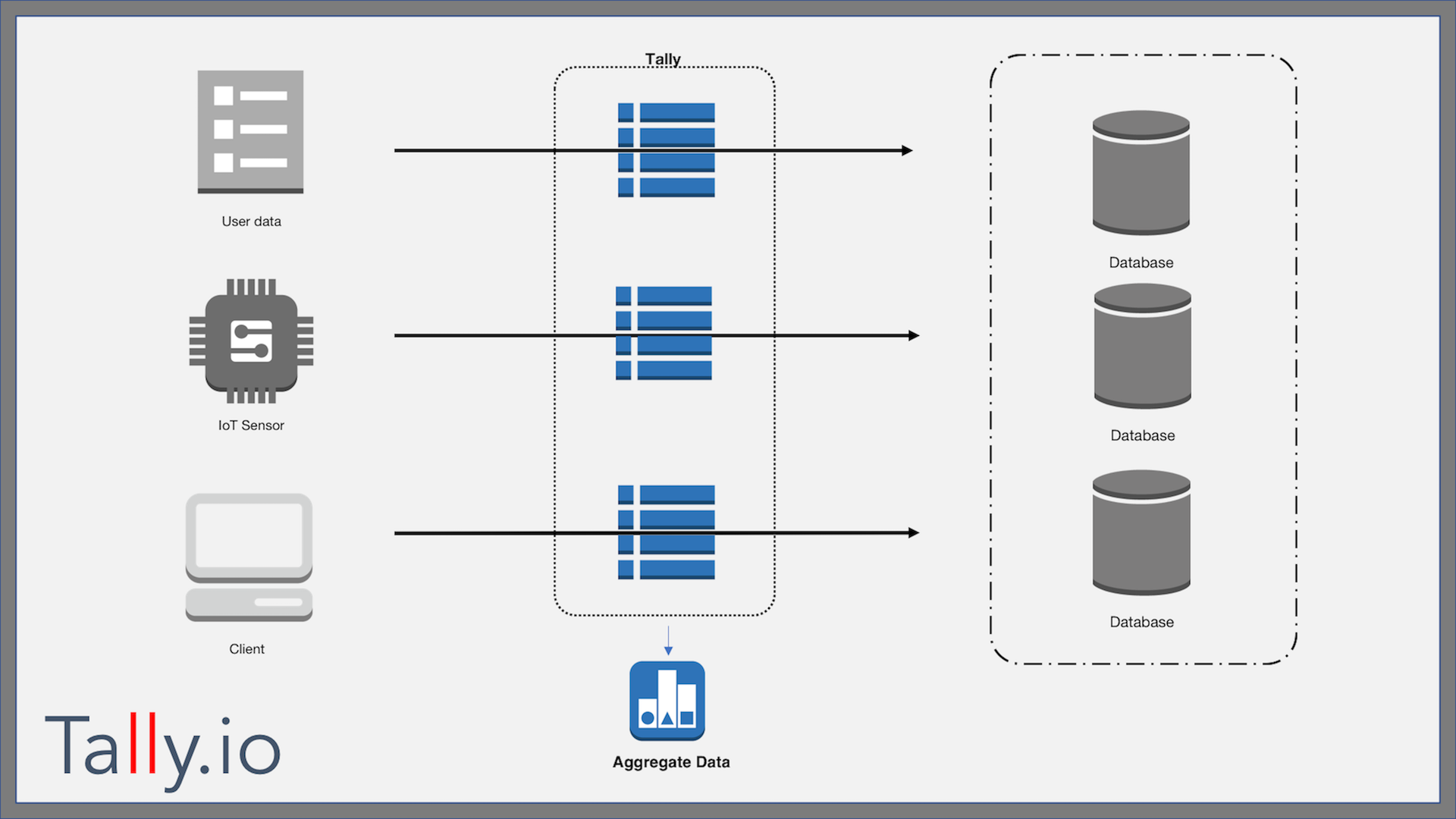
How it Works
Tally is designed to plug-in to any architecture. It sits between your API layers, and scales for any dataset. Just tell tally what to keep track of.
Here a few example data sources that would benefit from Tally integration:
- Log and Pattern Analysis
- Internet of Things(IoT) Sensor Data
- User Activity Monitoring